


目次
記事の要約
- 米国Anote, Inc.が日本語LLM評価・ファインチューニングプロジェクトを開始
- 高品質な日本語データ不足に対処し、AI開発企業・研究機関との連携を目指す
- エンドツーエンドのMLOpsプラットフォームでLLM導入を支援
米国Anote, Inc.が日本語LLM評価・ファインチューニングプロジェクトを開始
米国ニューヨークに本社を構えるAnote, Inc.は、株式会社チャネルブリッジと連携し、日本語の大規模言語モデル(LLM)の評価と性能向上を目的とした新たな取り組みを開始したことを発表した。このプロジェクトは、生成AIモデルのトレーニングと評価のための高品質な日本語データの不足に対処するために設計された。
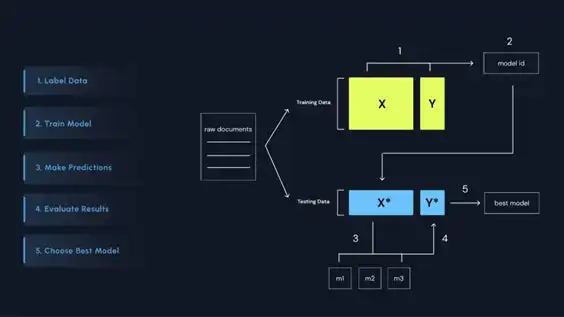
本日より、日本国内に拠点を置くAI開発企業または研究機関を対象に、限定パイロットプログラムへの参加申請受付を開始する。Anoteは、ユーザーのデータに最適な大規模言語モデル(LLM)を構築できるエンドツーエンドのMLOpsプラットフォームを提供し、データアノテーションからファインチューニング、推論、評価、統合までをサポートする。
このプラットフォームでは、GPT、Claude、Llama3、MistralといったゼロショットLLMと、ドメイン固有のトレーニングデータでファインチューニングされたLLMを比較できる評価フレームワークが提供される。また、生の未構造データをLLM対応フォーマットに変換するデータアノテーションインターフェースを備えており、専門家の知見をトレーニングプロセスに組み込むことで、モデル精度を向上させることが可能だ。
Anoteプラットフォームの主な特長
| 項目 | 詳細 |
|---|---|
| エンドツーエンドMLOps | アノテーション、ファインチューニング(LoRA/QLoRA/RLHF対応)、推論、評価、統合を一括サポート |
| マルチモデル比較 | GPT-4o、Claude 3.5、Llama 3、Mistralなどとファインチューニング済みモデルを日本語データで比較 |
| 評価フレームワーク | Cosine Similarity、Rouge-L、LLM Eval、Answer Relevance、Faithfulness等でモデル性能を多面的に評価 |
| タスク対応 | テキスト分類、固有表現抽出(NER)、全文書型QA、プロンプトQAに対応 |
| API・SDK | 最適モデルを業務環境に即時統合可能 |
MLOpsプラットフォームについて
MLOpsプラットフォームとは、機械学習モデルの開発から運用までの一連のプロセスを効率化するためのツール群のことを指す。以下のような特徴がある。
- モデル開発の迅速化
- 運用環境へのスムーズな移行
- 継続的なモデル改善
AnoteのMLOpsプラットフォームは、データアノテーションからモデルの評価、統合までを包括的にサポートし、企業が自社のデータでカスタムLLMを構築・運用することを可能にする。これにより、日本語LLMの性能向上と、より優れた日本語AIの構築・検証が期待される。
日本語LLM評価・ファインチューニングプロジェクトに関する考察
Anote, Inc.が開始した日本語LLM評価・ファインチューニングプロジェクトは、日本語AIの性能向上に大きく貢献する可能性を秘めている。特に、高品質な日本語トレーニングデータの不足という課題に対し、データアノテーションインターフェースや専門家の知見を活用することで、モデル精度向上が期待できるだろう。
今後の課題としては、収集したデータの偏りや、評価基準の客観性をどのように担保するかが挙げられる。これらの課題に対しては、多様なデータソースからの収集や、公開型LLM評価データセット・指標・リーダーボードの導入が有効な解決策となるだろう。
将来的には、このプロジェクトを通じて、日本語に最適化されたLLMが開発され、様々な分野でのAI活用が促進されることが期待される。また、Anoteプラットフォームが、日本語AI開発者・研究者にとって不可欠なツールとなる可能性も大いにあるだろう。
参考サイト/関連サイト
- PR TIMES.「米国ニューヨーク発のAnote, Inc、日本語LLM評価・ファインチューニングプロジェクトを始動 | 株式会社チャネルブリッジのプレスリリース」.https://prtimes.jp/main/html/rd/p/000000006.000130232.html, (参照 2025-04-29).
